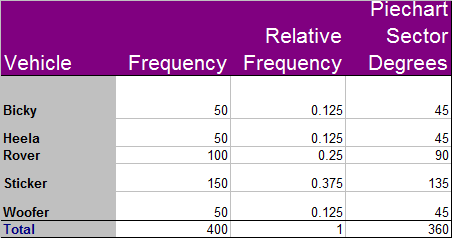
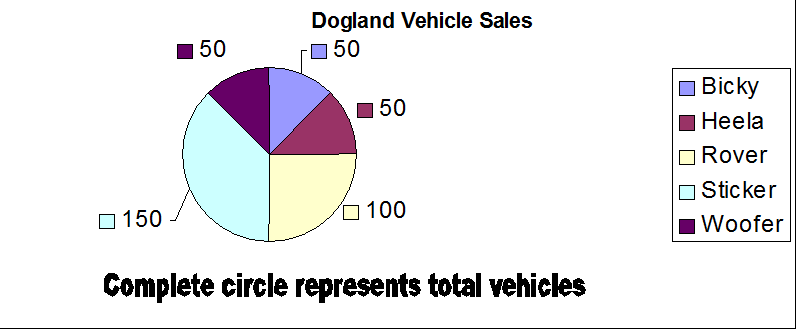
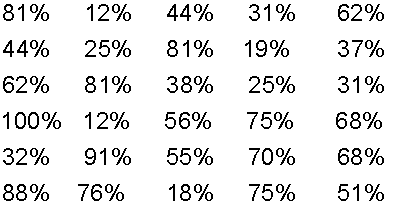This is a measure of how much the data varies from the mean.
\[ s = \sqrt{\text{variance}}
\]
Variance is the mean of the squares minus the square of the mean.
\[
\text{Variance}
= \frac{\sum x^{2}}{n}
\;-\;
\left( \frac{\sum x}{n} \right)^{2}
\]
A standard deviation of zero indicates that the data and the mean are effectively the same.
Two formulae are given by the SQA to calculate the standard deviation:
\[
s = \sqrt{
\frac{
\sum (x - \bar{x})^{2}
}{
n - 1
}
}
\]
and
\[
s = \sqrt{
\frac{
\sum x^{2} \;-\; \frac{(\sum x)^{2}}{n}
}{
n - 1
}
}
\]
Using the first equation
- Find the mean by adding the data and dividing by n
- Find the difference between the data and the mean (x̄)
- Square these differences
- Add up the total of the squared differences
- Plug into the first equation given in the test paper
Using the second equation
- Square the data to get \( x^2 \)
- Find totals \( \Sigma x \) and \( \Sigma x^2 \)
- Square the total \( \Sigma x \) and divide by n
- Plug into the second equation given in the test paper
Example
Calculate the standard deviation of the numbers:
101, 105, 133, 142, 185, 186
First Equation
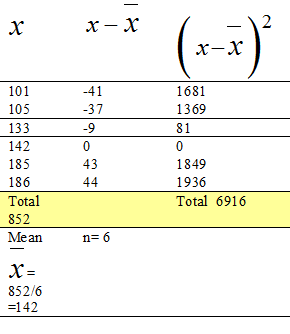
- Find the mean
- Find the differences from the mean
- Square the differences
- Add the squared differences
- Substitute into the formula
\[
s =
\sqrt{
\frac{
\sum (x - \bar{x})^{2}
}{
n - 1
}
}
\]
\[
=
\sqrt{
\frac{
6916
}{
6 - 1
}
}
\]
\[
=
\sqrt{
\frac{6916}{5}
}
\]
\[
= 37.1914
\]
Using equation 2

- Square the data
- Find totals \( \Sigma x \) and \( \Sigma x^2 \)
- Square \( \Sigma x \) and divide by n
- Substitute into the formula
\[
s =
\sqrt{
\frac{
\sum x^{2} \;-\; \frac{(\sum x)^{2}}{n}
}{
n - 1
}
}
\]
\[
s =
\sqrt{
\frac{
\color{red}{127900} \;-\; \frac{\color{blue}{852}^{2}}{6}
}{
6 - 1
}
}
\]
\[
s =
\sqrt{
\frac{
127900 \;-\; \frac{725904}{6}
}{
5
}
}
\]
\[
s =
\sqrt{
\frac{
127900 - 120984
}{
5
}
}
\]
\[
s =
\sqrt{
\frac{6916}{5}
}
\]
\[
s = \sqrt{1383.2}
\]
\[
s = 37.1914
\]
Changing all of the numbers by the same amount does not affect the standard deviation.
Example
The standard deviation of:
101, 105, 133, 142, 185, 186
is the same as the standard deviation of:
1, 5, 33, 42, 85, 86
and
4, 8, 36, 45, 88, 89
Interactive - Standard Deviation




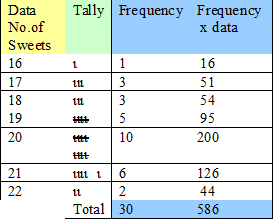 \[
\text{mean}
= \frac{\text{total number of sweets}}{\text{number of packets}}
\]
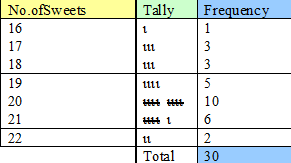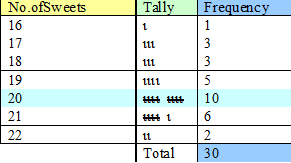
\[
= \frac{586}{30}
\]
\[
= 19 \frac{16}{30}
\]
\[
= 19 \frac{8}{15}
\]
\[
= 19.533333
\]
\[
\text{mean}
= \frac{\text{total number of sweets}}{\text{number of packets}}
\]
\[
= \frac{586}{30}
\]
\[
= 19 \frac{16}{30}
\]
\[
= 19 \frac{8}{15}
\]
\[
= 19.533333
\]